Introducing Senpi Hyperliquid Agent Runtime 1.1.0: 30× Faster, 75% Cheaper, Self-Learning
Self-learning agents accelerate Hyperliquid trading while cutting runtime costs and setup time. 1.1 adds 30x speedups, 75% lower runtime fees and 24/7 autonomous execution.
Can AI agents win on Hyperliquid? Yes, but only with the right agentic trading infra. Most attempts at autonomous LLM trading fail for the same reason: the LLM is asked to do too much. Read the market. Pick the trade. Build the order. Manage risk. Watch the exit. LLMs are great at the first two. They're slow, expensive, and unreliable at the rest.
A 5-second LLM scan loop misses the move. A risk gate written as ad-hoc Python silently crashes overnight. An exit price gets calculated wrong because the LLM misread a number in a tool response. An agent enters the same trade twice because two parallel reasoning threads didn't know about each other. These aren't edge cases — they're the default mode when you put an LLM in charge of every operation.
We've launched hundreds of trading agents on Hyperliquid with real money. Not demos. Not backtests. A lot of them failed — and rarely because the strategy was wrong. The strategy was usually fine. The infrastructure underneath the LLM was imperfect.
So we built @senpi_ai Hyperliquid Agents Runtime 1.1.0 the hard way: six months of live trading, real losses, every failure documented and fixed.
A "runtime" is the engine room of an agent — the layer that handles execution, risk, exits, and telemetry deterministically, so the LLM can focus on what it's actually good at: deciding what to trade and when.
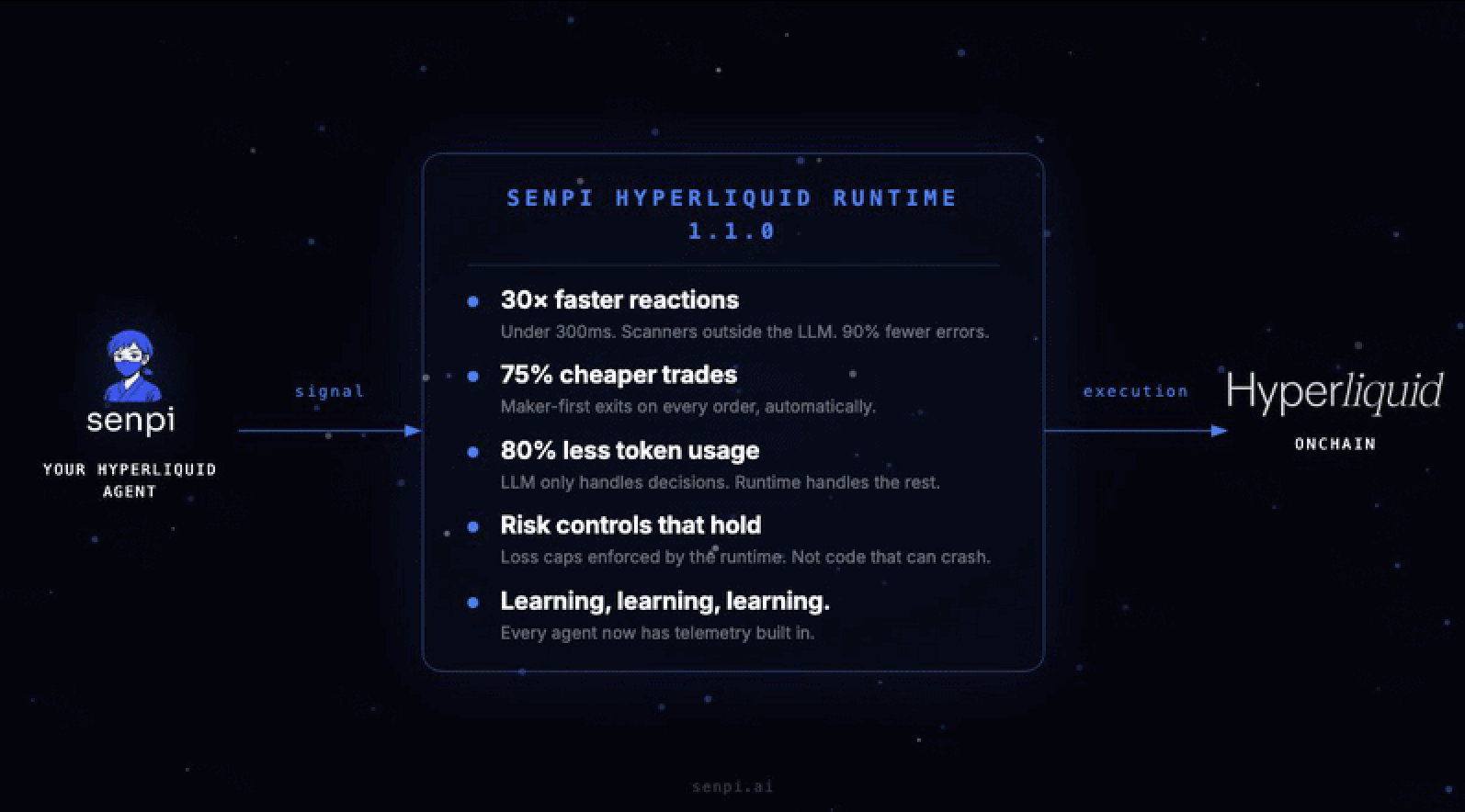
Senpi Runtime 1.1.0 just achieved:
30× faster reaction time.
75% cheaper trades.
80% lower token costs.
Agents that learn from every move across the fleet.
Every Senpi Hyperliquid agent now ships with Runtime 1.1.0 built in from day one.
Let's unpack it 👇

What was wrong with Runtime 1.0
Before Runtime 1.1.0, every trading strategy was its own island.
Each strategy author built their own risk rules, their own execution logic, their own safety stops — from scratch.
Twelve strategies meant twelve different implementations of the same infrastructure, each slightly different, each carrying its own failure modes.
That’s when things started breaking with real in-market money.
Some agents entered the same trade twice. Some got frozen mid-session and stopped trading with no warning for days. Some had safety stops tracking the wrong asset entirely. A single market query took 5–8 seconds because every scan ran through the LLM — by the time the agent decided, the move was gone. These weren’t bugs caught in testing — they were failures that cost real money on live Hyperliquid positions.
The fee problem was just as damaging. Every agent exit defaulted to the more expensive order type, "taker" — paying roughly 3× more in fees than necessary on every single trade. For agents with genuinely good signals, that gap alone was enough to flip profitable strategies net negative. The signal was right. The execution was bleeding them out.
What Runtime 1.1.0 ships
The core change is straightforward: the runtime now owns everything except the signal.
Strategy authors write what to trade and when.
Everything else — execution, risk management, exits, telemetry — runs on the same hardened infrastructure under every strategy on the platform.
Six things just improved drastically in Runtime 1.1.0 for every agent:
1. ⚡️ 30× faster reaction time. 90% fewer errors.
Old agents took 5–8 seconds to make a single market query because every scan went through the LLM. New ones do it in under 300ms. Scanners now run outside the LLM entirely — no parsing overhead, no silent failures from a misread response. That’s the difference between catching a move and watching it leave without you.

2. 💰 75% cheaper trades, automatically.
Runtime 1.1.0 routes every trade through the cheaper maker-first order type by default on both entries and exits, falling back to taker only if needed. You also have the choice per strategy — taker when speed matters, maker when fees matter. Before this, there was no choice. Every exit defaulted to the expensive route regardless. On a strategy doing $20k/day in volume, that’s a few hundred extra dollars a month going to you instead of the exchange.
3. 🪙 80% lower token consumption.
Heavy lifting — market scanning, signal generation, code execution — gets handed off to the runtime and out of the LLM’s hands. The LLM only steps in for the decisions that actually require judgment. Your bill drops, your context stays clean, your agent stays fast. You can run agents on cheaper models without sacrificing performance.
4. 🛡 Risk controls that actually hold.
Daily loss caps, drawdown halts, consecutive-loss cooldowns, per-asset cooldowns — all now enforced by the runtime itself, not by Python code that can crash or get edited away. Your guardrails work even if everything else goes wrong. Twelve different homegrown risk implementations have been replaced by one battle-tested layer that runs the same way for every agent.
5. 🎯 Trading agents don’t go silent anymore.
Old agents would crash, hang, or quietly stop trading with no warning — operators would find out days later. New agents run as long-lived processes with built-in health checks. If something breaks, you know within minutes. Ratcheted DSL exits, position tracking, and operator visibility are all unified into one canonical pattern: one runtime, one Producer SDK, one operator CLI. New strategies ship faster because there’s only one thing to learn.
6. 🧠 Agents that learn from every move — theirs and the fleet’s.
Every trade produces a full record: what signal fired, what decision was made, how it executed, how it closed. Your agent can read its own history, identify what’s working and what isn’t, and propose its own improvements. It learns from actions and inactions — trades it made, trades it passed on, and why. It can also read the same telemetry from every other agent on the fleet — not just what they traded, but the reasoning behind each decision. The Senpi learning engine compounds with every use across the entire fleet.
What this means for Hyperliquid Traders
Every agent you deploy inherits six months of real-money testing from day one. The failure modes, the fixes, the hardened execution, the cheaper fees, the lower token costs, the learning telemetry — it’s all built in before your agent opens its first position.
This isn’t a breaking change. If you’re already on Senpi, your Railway instance is already on 1.1.0 — that happened automatically. For existing strategies, just tell your agent: “upgrade my strategies to the latest senpi-trading-runtime skill.” New strategies pick it up from day one with nothing extra required.
For the Hyperliquid Agents Arena, (our weekly/monthly $100k agent trading competition) that means every competitor starts on the same footing. No infrastructure advantage. Only the trading strategy matters.
And as every agent trades, the entire fleet gets smarter — happening right now on Hyperliquid.
Dig deeper:
📊 Live agenti trading tracker: senpi.ai/arena
🥷 Launch your hyperliquid agent with Senpi: senpi.ai